对于mysql,redis,Kafka,zookeeper磁盘缓存技术使用分析
大部分组件是基于磁盘存储的,但由于CPU速度和磁盘速度之间的鸿沟,都会使用缓存技术来提高性能,缓存简单来说就是一块内存区域,首先将从磁盘读到的数据放在缓存中,之后查询或修改时直接操作缓存,对于缓存中的数据则以一定的频率刷新到磁盘上,怎样缓存,缓存多少,何时刷新,这些影响着整个组件的性能。在看过一些关于mysql等组件的架构原理后,会发现不论是基于磁盘的mysql数据库和Kafka消息中间件zookeeper分布式协调框架,还是基于内存的redis数据库,它们都设计了完善的内存和磁盘之间数据交互实现。在快速读取数据和持久化保存数据中做出平衡。缓存还有空间和时间读取规则,从空间角度热点数据相邻区域的数据不久之后也会被访问,从时间角度热点数据第一次访问后还会被继续访问到。
mysql磁盘缓存(仅在使用Innodb引擎下)
分析mysql将哪些数据进行缓存时,可以找到它的根源来看,即mysql中innodb引擎的缓存池。
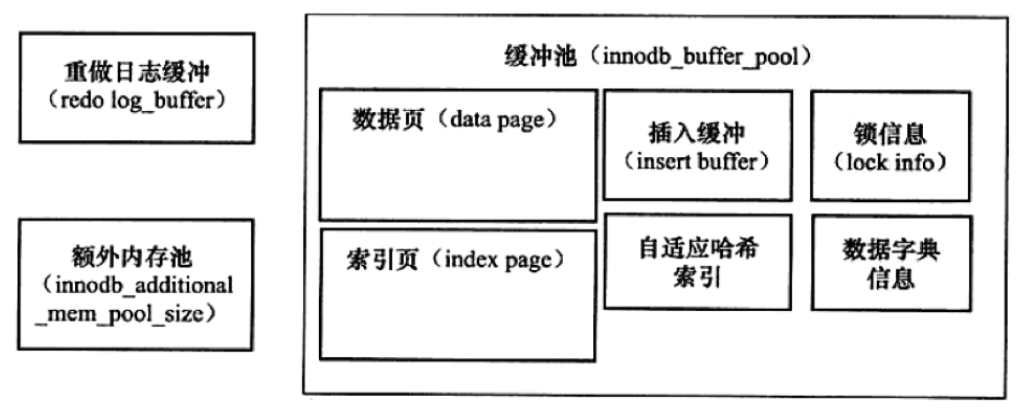
当然innodb中可以设置多个这样的缓存池实例,从而增加数据库的并发能力,缓存池的大小是可以配置的,缓存池中每个页的大小为16KB,通过LRU算法来管理缓存池,当LRU列表中的页被修改后,因为与磁盘中的数据产生不一致将该页称为脏页,这是数据库会通过CHECKPOINT机制将脏页刷回磁盘,脏页也会存在与Flush列表中,Flush与LRU列表互不影响,LRU列表管理缓存池中页的可用性,而Flush列表管理页刷新回磁盘,脏页数量可以通过命令来查询。
下面需要关注的是与磁盘文件相关联的缓存
重做日志缓存
重做日志缓存为innodb引擎独有,其对应着reco log文件,默认为8MB,因为一般情况下每秒钟会将重做日志刷新到日志文件,所以不需要设置的太大,通常在以下三种情况下会将重做日志缓存中的内容刷新到磁盘上重做日志文件中。
- Master Thread每秒钟将重做日志缓存刷新到重做日志文件
- 每个事务提交时会将重做日志缓存刷新到重做日志文件(由innodb_flush_log_at_trx_commit控制)
- 当重做日志缓存剩余空间小于1/2时,将重做日志缓存刷新到重做日志文件
因为缓存和磁盘数据不可能实时保持一致,为了防止数据丢失,当前事务数据库都普遍采用Write ahead log策略,即当事务提交时先写重做日志,再修改页,当发生宕机导致数据丢失后,可以通过日志来进行数据恢复,保证了事务中持久性的要求。为得到高可靠性可以设置多个镜像日志组。
数据页索引页缓存
这里用到了innodb引擎的关键特性,插入缓存(Insert/Change Buffer)来对数据进行操作,Innodb对每张表都设置了主键,主键是行的唯一标识符,通常行记录的插入顺序也是安装主键递增的顺序进行插入,因此插入聚集索引一般不需要随机读取,但表中还会存在多个非聚集的辅助索引,当进行插入时,数据页的存放还是按聚集索引来顺序存放,而对于索引页中非聚集的辅助索引页更新存在离散访问,这样随机的读取会导致性能的下降,所以使用Insert Buffer来对辅助索引进行缓存,再根据一定频率与辅助索引页进行merge合并。
二进制日志缓存(binary log)
二进制日志记录了对mysql数据库执行更改的所有操作,但不包含对数据库本身没有修改的操作,如select和show,二进制日志用于数据库的恢复,主从数据同步的复制,对日志中的信息进行安全审计。
注意,当使用事务的表存储引擎时,所有未提交的二进制日志会被记录到缓存中,等事务提交时将缓存中的二进制日志写入到二进制日志文件中,binlog_cache_size是基于会话而不是全局的,默认大小32K。
默认情况下二进制日志并不是每次写的时候都会同步到磁盘,需要设置sync_binlog值来进行调整,默认值为0,表示MySQL不控制binlog的刷新,由文件系统自己控制它的缓存的刷新。这时候的性能是最好的。
Undo日志缓存
undo是逻辑日志,根据每行记录来进行记录,用来帮助事务回滚及MVCC的功能实现非锁定读取,undo日志存放于共享表空间里,通过全局动态参数innodb_purge_batch_size来设置每次purge需要清理的undo page数量,默认为300.
但凡用了缓存肯定需要刷回磁盘,而刷回磁盘的操作由哪些线程来进行,一步步来就能发现mysql后台主要有以下四种线程。
Master Thread:主要负责将缓存池中的数据异步刷新到磁盘中去(包括页刷新,合井缓存插入, 回收undo页
IO Thread:主要负责请求的回调处理。((InnoDB 中请求大量使用了A,提高处理性 ) write , read , insert buffer , log IO thread .
Purge Thread:事务被提交后,所需undolog可能不使用,用来回收undo页
Page Cleaner Thread:用来刷新脏页
以上便是mysql涉及到缓存和磁盘相关联的数据更新情况,主要包含四种日志和数据的同步。
Redis磁盘缓存
严格意义来说,redis与其他组件还是不同的,redis原生就支持在内存中使用,而将数据存放到磁盘中反而是可以配置的,并非一定需要将数据持久化,redis的主要作用是缓存数据,所以数据的持久保存应该由后端数据库来做,业务的场景也应该是先查redis,如果不存在则再去数据库中查找,过于依赖redis的数据持久化,可能会造成数据返回不一致。
redis 的持久化机制有两种,第一种是快照,第二种是 AOF 日志。快照是一次全量备份,AOF 日志是连续的增量备份,这与之后要说zookeeper有点类似。快照是内存数据的二进制序列化形式,而AOP日志记录的是内存数据修改的指令记录文本,AOP日志在长期的运行过程中会逐渐变大,所以也会不断进行覆盖。快照可以配置频率,“save * ”:保存快照的频率,第一个表示多长时间,单位是秒,第二个“*”表示至少执行写操作的次数,在一定时间内至少执行一定数量的写操作时,就自动保存快照,可设置多个条件。
AOP日志
redis在收到客户端指令,经过校验后会将该指令存储到AOF日志中,再去执行指令,保证在宕机后也能通过AOP日志的指令重放恢复到宕机前的状态。对AOP日志进行写操作时,实际上是将内容写到了内核为文件描述符分配的一个内存缓存中,然后内核会异步将脏数据刷回磁盘。linux提供fsync指令可以指定文件强制从缓存中刷新到磁盘,但如果redis实时调用fsync进行日志同步,这种磁盘IO操作将会严重影响redis高性能。一般redis是每隔1s执行一次fsync操作,周期可以配置,或者也可以永不执行,让操作系统来进行调度,也可以每个指令执行一次。
Kafka磁盘缓存
Kafka中大量使用了页缓存,这是Kafka实现高吞吐的重要因素之一 。用过Java的都知道两点事实:
- 对象的内存开销非常大,通常会是真实数据大小的几倍甚至更多,空间使用率低下。
-
Java的垃圾回收会随着堆内数据的增多而变得越来越慢。
基于这些因素,使用文件系统并依赖于页缓存的做法明显要优于维护一个进程内缓存或其他结构,至少我们可以省去了一份进程内部的缓存消耗,同时还可以通过结构紧凑的字节码来替代使用对象的方式以节省更多的空间。如此,我们可以在32GB的机器上使用28GB至30GB的内存而不用担心GC所带来的性能问题。此外,即使Kafka服务重启,页缓存还是会保持有效,然而进程内的缓存却需要重建。这样也极大地简化了代码逻辑,因为维护页缓存和文件之间的一致性交由操作系统来负责,这样会比进程内维护更加安全有效。
换个角度看,Kafka其实也是一种数据库,生产者就是在insert数据,而消费者就是在select数据,唯一与磁盘缓存进行交互就是borker,borker将生产的数据直接放到缓存中,当消费数据时通过零拷贝技术将缓存中的数据放到socket进行传输,当缓存中没有所需的数据时才会加载磁盘。Kafka的使用场景大部分操作都是顺序读写,采用文件追加的方式来写入消息,即使使用磁盘,性能依旧很高。
Kafka把topic中每个parition大文件分成多个segment小文件段,索引文件负责数据的查找,Kafka的索引文件以稀疏索引的方式构造,分为偏移量索引和时间戳索引,稀疏索引的方式能够降低索引在内存中占用率。
Kafka只负责将消息写到系统缓存中,并不保证脏数据何时会被刷新到磁盘上,可以使用l o g . f l u s h . i n t e r v a l .
m e s s a g e s 、l o g . f l u s h . i n t e r v a l . m s 等参数来控制,Kafka消息的可靠性是依赖于多副本机制,而不是由同步刷盘这种严重影响性能的行为来保障。
zookeeper磁盘缓存
zookeeper在内存中维护着类似于树形文件系统的节点数据模型,其中包含了整棵树的内容,所有的节点路径,节点数据等。代码中使用DataTree的数据结构来保存这些信息,底层是使用一个ConcurrentHashMap键值对结构,既然在内存中有数据必然需要在磁盘上有对应的持久化,类似于redis,zookeeper中也分为事务日志和快照数据。
事务日志
存放于dataLogDir配置的路径下,默认存放在dataDir,使用日志中第一条事务记录的ZXID命名,事务日志每个文件都是64MB,因为ZooKeeper 对事务日志文件的磁盘空间进行预分配,客户端的每一次事务操作,ZooKeeper 都会将其写入事务日志文件中。因此,事务日志的写入性能直接决定了ZooKeeper 服务器对事务请求的响应,文件的不断追加写入操作会触发底层磁盘IO为文件开辟新的磁盘块,为了避免磁盘Seek的频率,提高磁盘IO的效率,预先进行磁盘空间分配。当事务操作写入文件流的缓存中,需要将缓存数据强制刷入磁盘,这里可以通过forceSync参数来配置,forceSync=yes则每次事务提交的时候将写入操作同步缓存并刷盘,forceSync=no表示让系统来调度刷盘频率。
zookeeper更新操作过程:先写事务日志,再写内存,周期性落到磁盘(刷新内存到快照文件)。事务日志的对写请求的性能影响很大,快照文件和事务日志文件分别挂在不同磁盘,保证dataLogDir所在磁盘性能良好、没有竞争者。