从TheadLocalMap看哈希碰撞后开放寻址法的实现过程
本来想说ThreadLocal,但看到了ThreadLocalMap中对哈希碰撞是采用开放寻址法来实现的,觉得很有意思,hash使用的场景很多,散列表就是一种高效而常用的数据结构,能将查找的时间复杂度降到O(1),它通过哈希函数来生成一个 hashcode 值,从而对数据进行一一定位,虽然现在的哈希函数已经能做到很好的随机,但还是会有冲突发生,也就是不同的对象经过哈希函数的计算,生成了相同的 hashcode 值。当哈希冲突发生时,一般有以下几种方式来处理:
- 拉链法:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表进行存储,之前接触的数据结构如HashMap或者其他字典结构,都是采用拉链法。
- 开放定址法:一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
- 再哈希:又叫双哈希法,有多个不同的Hash函数,当发生冲突时使用第二个,第三个….等哈希函数计算地址,直到无冲突。
拉链法的实现可以去看HashMap的源码,以及当单链过长时会自动转换为红黑树结构,插入链表时还要注意是头插法还是尾插法。
先说一下ThreadLocal,是一个很重要的东西,出现于Thead类源码中。
|
1 2 |
ThreadLocal.ThreadLocalMap threadLocals = null; |
ThreadLocal中包含以下方法和类型
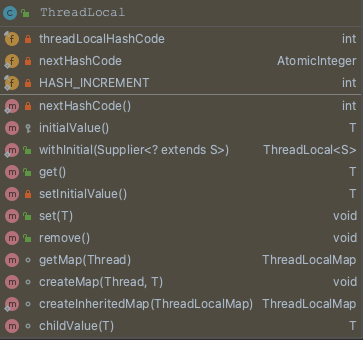
提供三个公共方法来进行操作,分别是set,get,remove,看起来很简单的样子,Threadlocal而是一个线程内部的存储类,可以在指定线程内存储数据,数据存储以后,只有指定线程可以得到存储数据。实际上是ThreadLocal的静态内部类ThreadLocalMap为每个Thread都维护了一个数组table,ThreadLocal通过Thread确定数组下标,而这个下标就是value存储的对应位置。
先看初始化过程,ThreadLocal是延迟构建的,只有当有数据要放进来的时候才进行创建。
|
1 2 3 4 5 6 7 8 |
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { table = new Entry[INITIAL_CAPACITY]; int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); } |
set方法的实现,通过 hashCode 计算的索引位置 i 处如果已经有值了,会从 i 开始,通过 +1 不断的往后寻找, 直到找到索引位置为空的地方,把当前 ThreadLocal 作为 key 放进去。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
private void set(ThreadLocal<?> key, Object value) { //获取当前数组和长度 Entry[] tab = table; int len = tab.length; //通过hash计算要存储的下标位置 int i = key.threadLocalHashCode & (len-1); //考虑存在hash冲突的情况,如果当前坐标已经有数据了,就调用nextIndex获取下一个位置 for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { ThreadLocal<?> k = e.get(); if (k == key) { e.value = value; return; } if (k == null) { replaceStaleEntry(key, value, i); return; } } //终于找到新的空位置 tab[i] = new Entry(key, value); int sz = ++size; if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash(); } private static int nextIndex(int i, int len) { //判断下一个位置是否超过数组长度,如果超过了,就从0开始 return ((i + 1 < len) ? i + 1 : 0); } |
因为set方法的特殊,get方法也需要有点改变
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
private Entry getEntry(ThreadLocal<?> key) { //计算存储的下标 int i = key.threadLocalHashCode & (table.length - 1); Entry e = table[i]; //如果当前下标位置的数据的key于查询的key相同,则直接返回 if (e != null && e.get() == key) return e; else //key不同,说明有冲突,需要往下查找 return getEntryAfterMiss(key, i, e); } private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { Entry[] tab = table; int len = tab.length; //一直找到e不为空 while (e != null) { ThreadLocal<?> k = e.get(); if (k == key) return e; if (k == null) //处理key为null的节点 expungeStaleEntry(i); else //增加i i = nextIndex(i, len); e = tab[i]; } return null; } |
ThreadLocal和Synchronized都是为了解决多线程中相同变量的访问冲突问题,不同的点是
- Synchronized是通过线程等待,牺牲时间来解决访问冲突
- ThreadLocal是通过每个线程单独一份存储空间,牺牲空间来解决冲突,并且相比于Synchronized,ThreadLocal具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问到想要的值。
正因为ThreadLocal的线程隔离特性,使它的应用场景相对来说更为特殊一些。当某些数据是以线程为作用域并且不同线程具有不同的数据副本的时候,就可以考虑采用ThreadLocal。