CSDN个人博客阅读评论信息的爬取
用来爬取CSDN上个人博客的信息,包括阅读次数,评论数等等
因为CSDN更换了界面,原来的爬虫已经失效,所以我重新写了一个爬虫,可以精准的爬取到每篇文章阅读次数和评论次数的变化,并将总结出来的信息发送到邮箱里,
项目中有两个文件,csdn_old.py是旧版CSDN界面的爬虫,使用了BeautifulSoup来进行爬取信息,它的功能也是将每日博客信息的变化值总结下来发送到邮箱里,csdn_new.py是新版的爬虫,全部使用re来提取信息,并添加了评论次数的检测。
代码说明:
1.需要配置对应的数据库文件,因为里面保存了博客前一日的全部信息
2.需要发送邮件,必须有对应的邮箱账号和密码才能使用
3.我的代码是放到服务器上每天定时运行的,没有服务器的同学可以联系我,也可以放到我的服务器上。
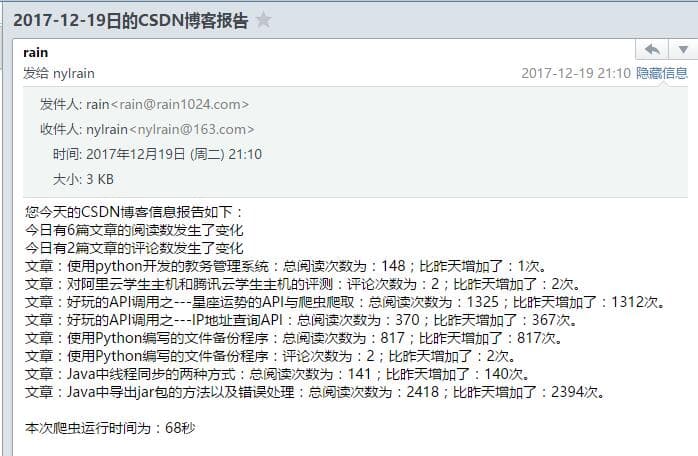
实现效果
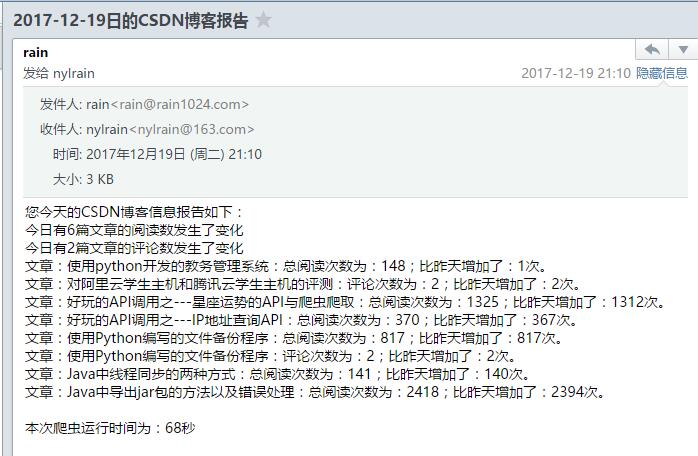
Gitee上的地址https://gitee.com/rainweb/CSND
csdn_new.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 |
#-*- coding=utf8 -*- import sys reload(sys) sys.setdefaultencoding( "utf-8" ) import urllib2 import re import MySQLdb import datetime import time import smtplib from email.mime.text import MIMEText from email.header import Header def email(text ,toemail): sender = "" #发送方的邮箱 password = "" #邮箱的授权码 receiver = toemail #接收方的邮箱 data_time = time.strftime("%Y-%m-%d") subject = data_time + "日的CSDN博客报告" #title邮件标题 words = text #text邮件内容 smtpserver = 'smtp.exmail.qq.com' msg = MIMEText(words, 'plain', 'utf-8')#中文需参数‘utf-8',单字节字符不需要 msg['Subject'] = Header(subject, 'utf-8') #邮件标题 msg['from'] = sender #发信人地址 msg['to'] = receiver #收信人地址 smtp = smtplib.SMTP_SSL("smtp.exmail.qq.com", 465) smtp.connect('smtp.exmail.qq.com') smtp.login(sender, password) smtp.sendmail(sender, receiver, msg.as_string()) smtp.quit() print data_time + "的邮件发送成功!" # 实现下载HTML网页源码的函数,url为地址 def DownLoad_Html(url): try: html = urllib2.urlopen(url).read() except urllib2.URLError as e: print "error" print e.code # 可以打印出来错误代号如404。 print e.reason # 可以捕获异常 html = None return html def operator_SQL(flag,update=None): # 将获取的数据存入数据库中 try: conn = MySQLdb.connect( host='127.0.0.1', port=3306, user='root', passwd='root', # user='', # passwd='', db='test', charset='utf8', ) except: conn = MySQLdb.connect( host='127.0.0.1', port=3306, # user='root', # passwd='root', user='', passwd='', db='test', charset='utf8', ) cur = conn.cursor() if flag == 1: res = cur.execute("select * from csdn_article") cur.execute( 'insert into csdn_article values("%s","%s", "%s", "%s", "%s", "%s")' % (res + 1, update[0], update[1], update[2],update[3], 0 )) elif flag == 2: cur.execute("update csdn_article set article_read="+str(update[1])+" where article_id = "+str(update[0])) cur.execute("update csdn_article set change_read=" + str(update[3]) + " where article_id = " + str(update[0])) elif flag == 3: res = cur.execute("select article_read from csdn_article where article_id="+str(update)) if res == 1: res = cur.fetchmany(res)[0][0] elif res == 0: res = -1 return res elif flag == 4: res = cur.execute("select article_comment from csdn_article where article_id=" + str(update)) if res == 1: res = cur.fetchmany(res)[0][0] return res elif flag == 5: cur.execute( "update csdn_article set article_comment=" + str(update[1]) + " where article_id = " + str(update[0])) # sql_list = list(cur.fetchmany(res)) # print sql_list[1].count(435) # if 435 in sql_list: # print '432432443242' cur.close() conn.commit() conn.close() def main(): starttime = datetime.datetime.now() article_all_list = [] text = '' comment_num = 0 read_num = 0 for i in range(1, 10000): url = 'http://blog.csdn.net/rain_web/svc/getarticles?pageindex=' + str(i) + '&pagesize=1&categoryId=0&' html = DownLoad_Html(url) if html == '': break title = re.findall('_blank">(.*?)<', html) read = re.findall('span>(.*?)<', html) id = re.findall('details/(.*?)"', html) article_title = title[0] article_read = int(read[0]) article_comment = int(read[1]) article_id = id[0] # 然后将每一篇文章里的数据放入一个列表里,再将这个列表放到大的列表里 article_list = [] article_list.append(article_id) article_list.append(article_read) article_list.append(article_title) article_list.append(article_comment) # 用于判断有没有阅读次数的改变,如果没有,则在评论次数前加标题 flag = 0 # 对每个值去数据库里查找,如果存在就进行比较,不相同则记录下来,并去数据库中修改,如果不存在,则插入这条数据 read = operator_SQL(3, article_id) # 阅读次数 -1 代表数据不存在,插入数据 if read == -1: operator_SQL(1, article_list) # 如果数据库中阅读次数和爬取的阅读次数不同 elif read != article_read: # 将阅读次数的差值记录下来 article_list.append(article_read - read) # print article_list[3] # 修改阅读次数 operator_SQL(2, article_list) # article_all_list.append(article_list) text = text + '文章:' + article_title + ':总阅读次数为:' + str(article_read) + ';比昨天增加了:' + str( article_read - read) + '次。' + '\n' read_num = read_num + 1 # break comment = operator_SQL(4, article_id) if comment != article_comment: # 修改次数 comment_list = [] comment_list.append(article_id) comment_list.append(article_comment) operator_SQL(5, comment_list) comment_num = comment_num + 1 text = text + '文章:' + article_title + ':评论次数为:' + str(article_comment) + ";比昨天增加了:" + str( article_comment - comment) + '次。' + '\n' text = "您今天的CSDN博客信息报告如下:" + '\n今日有' + str(read_num) + \ '篇文章的阅读数发生了变化\n' + '今日有' + str(comment_num) + '篇文章的评论数发生了变化\n' + text endtime = datetime.datetime.now() text = text + '\n本次爬虫运行时间为:' + str((endtime - starttime).seconds) + '秒' print text email(text, 'nylrain@163.com') if __name__=='__main__': main() |